

")












Thuật toán cây quyết định
Thuật toán cây quyết định cho ra kết quả là một tập luật của những dữ liệu huấn luyện có thuộc tính. Cây quyết định là một công cụ phổ biến trong khai phá và phân lớp dữ liệu
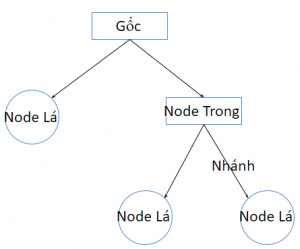
Đặc điểm của cây quyết định: là một cây có cấu trúc, trong đó:
- Root (Gốc): Là nút trên cùng của cây.
- Node trong: nút trung gian trên một thuộc tính đơn (hình Oval).
- Nhánh: Biểu diễn các kết quả của kiểm tra trên nút.
- Node lá: Biểu diễn lớp hay sự phân phối lớp (hình vuông hoặc chữ nhật)
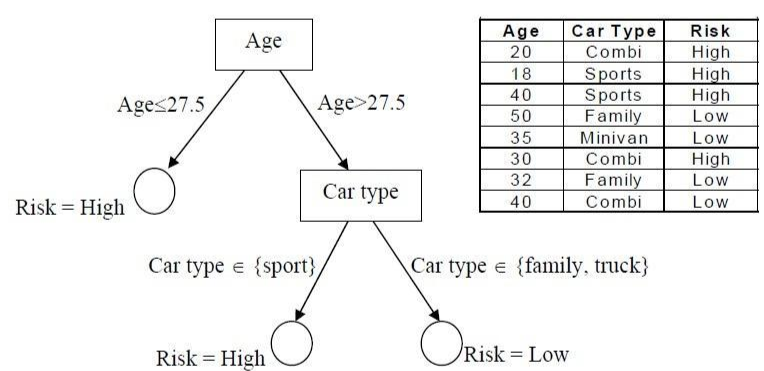
Ví dụ cây quyết định:
Xây dựng cây quyết định gồm 2 bước:
- Phát triển cây quyết định: đi từ gốc, đến các nhánh, phát triển quy nạp theo hình thức chia để trị.
Bước 1. Chọn thuộc tính “tốt” nhất bằng một độ đo đã định trước
Bước 2. Phát triển cây bằng việc thêm các nhánh tương ứng với từng giá trị của thuộc tính đã chọn
Bước 3. Sắp xếp, phân chia tập dữ liệu đào tạo tới node con
bước 4. Nếu các ví dụ được phân lớp rõ ràng thì dừng.
Ngược lại: lặp lại bước 1 tới bước 4 cho từng node con
- Cắt tỉa cây: nhằm đơn giản hóa, khái quát hóa cây, tăng độ chính xác
Thuật toán Hunt sử dụng trong C4.5, CDP,…
S={S1,S2,…,Sn} là tập dữ liệu đào tạo
C={C1,C2,…,Cm} là tập các lớp
Trường hợp 1: Si (i=1…n) thuộc về Cj => Cây quyết định là 1 lá
ứng Cj.
Trường hợp 2: S thuộc về nhiều lớp trong C.
- Chọn 1 test trên thuộc ơnh đơn có nhiều giá trị O={O1,..Ok}
(k thường bằng 2). - Test từ gốc của cây, mỗi Oi tạo thành 1 nhánh, chia S thành
các tập con có giá trị thuộc tính = Oi. Đệ quy cho từng tập
con => cây quyết định gồm nhiều nhánh, mỗi nhánh tương
ứng với Oi
Đánh giá thuật toán cây quyết định trong lĩnh vực khai phá dữ liệu
Thuận lợi:
- Quá trình xây dựng cây quyết định không dùng kiến thức về lĩnh vực dữ liệu đang nghiên cứu hoặc thông số đầu vào nào.
- Kết quả của quá trình huấn luyện (học) được biểu diễn dưới dạng cây nên dễ hiểu và gần gũi với con người.
- Nhìn chung, các giải thuật cây quyết định cho kết quả có độ chính xác khá cao.
Khó khăn:
-
- Đối với các tập dữ liệu có nhiều thuộc tính thì cây quyết định sẽ lớn (về chiều sâu cả chiều ngang), vì vậy làm giảm độ dễ hiểu.
- Việc xếp hạng các thuộc tính để phân nhánh dựa vào lần phân nhánh trước đó và bỏ qua sự phụ thuộc lẫn nhau giữa các thuộc tính.
- Khi dùng độ lợi thông tin (Information Gain) để xác định thuộc tính rẽ nhánh, các thuộc tính có nhiều giá trị thường được ưu tiên chọn.
Thuật toán C4.5
- Là sự phát triển từ CLS và ID3.
- ID3 (Quinlan, 1979)‐ 1 hệ thống đơn giản ban đầu
chứa khoảng 600 dòng lệnh Pascal - Năm 1993, J. Ross Quinlan phát triển thành C4.5 với
9000 dòng lệnh C.
Với những đặc điểm C4.5 là thuật toán phân lớp dữ liệu dựa trên cây quyết định hiệu quả và phổ biến trong những ứng dụng khai phá cơ sở dữ liệu có kích thước nhỏ. C4.5 sử dụng cơ chế lưu trữ dữ liệu thường trú trong bộ nhớ, chính đặc điểm này làm C4.5 chỉ thích hợp với những cơ sở dữ liệu nhỏ, và cơ chế sắp xếp lại dữ liệu tại mỗi node trong quá trình phát triển cây quyết định. C4.5 còn chứa một kỹ thuật cho phép biểu diễn lại cây quyết định dưới dạng một danh sách sắp thứ tự các luật if-then (một dạng quy tắc phân lớp dễ hiểu). Kỹ thuật này cho phép làm giảm bớt kích thước tập luật và đơn giản hóa các luật mà độ chính xác so với nhánh tương ứng cây quyết định là tương đương.
Tư tưởng phát triển cây quyết định của C4.5 là phương pháp Hunt đã nghiên cứu ở trên. Chiến lược phát triển theo độ sâu (depth-first strategy) được áp dụng cho C4.5.
Mã giả của thuật toán C4.5:
| Pseudocode:
· Kiểm tra case cơ bản · Với mỗi thuộc tính A tìm thông tin nhờ việc tách thuộc tính A · Chọn a_best là thuộc tính mà độ đo lựa chọn thuộc tính “tốt nhất” · Dùng a_best làm thuộc tính cho node chia cắt cây. · Đệ quy trên các danh sách phụ được tạo ra bởi việc phân chia theo a_best, và thêm các node này như là con của node |
(1) ComputerClassFrequency(T); (2) if OneClass or FewCases return a leaf; Create a decision node N; (3) ForEach Attribute A ComputeGain(A); (4) N.test=AttributeWithBestGain; (5) if (N.test is continuous) find Threshold; (6) ForEach T’ in the splitting of T (7) If ( T’ is Empty ) Child of N is a leaf else (8) Child of N=FormTree(T’); (9) ComputeErrors of N; return N |
C4.5 có những đăc điểm khác với các thuật toán khác, đó là: cơ chế chọn thuộc tính để kiểm tra tại mỗi node, cơ chế xử lý với những giá trị thiếu, việc tránh “quá vừa” dữ liệu, ước lượng độ chính xác và cơ chế cắt tỉa cây.
C4.5 dùng Gain-entropy làm độ đo lựa chọn thuộc tính “tốt nhất”.
Phần lớn các hệ thống đều cố gắng để tạo ra một cây càng nhỏ càng tốt, vì những cây nhỏ hơn thì dễ hiểu hơn và dễ đạt được độ chính xác dự đoán co hơn. Do không thể đảm bảo được sự cực tiểu của cây quyết định, C4.5 dựa vào nghiên cứu tối ưu hóa, và sự lựa chọn cách phân chia mà có độ đo lựa chọn thuộc tính đạt giá trị cực đại.
Hai độ đo được sử dụng trong C4.5 là information gain và gain ratio. RF(Cj,S) biểu diễn tần xuất (Relative Frequency) các case trong S thuộc về lớp Cj.
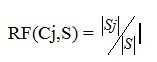 Với
Với ![]() là kích thước tập các case có giá trị phân lớp là Cj.
là kích thước tập các case có giá trị phân lớp là Cj.
![]() là kích thước tập dữ liệu đào tạo.
là kích thước tập dữ liệu đào tạo.
Chỉ số thông tin cần thiết cho sự phân lớp: I(S) với S là tập cần xét sự phân phối lớp được tính bằng:
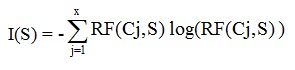
Sau khi S được phân chia thành các tập con S1, S2,…, St bởi test B thì information gain được tính bằng:
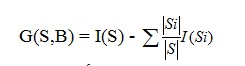
Test B sẽ được chọn nếu có G(S,B) đạt giá trị lớn nhất.
Tuy nhiên có một vấn đề khi sử dụng G(S,B) ưu tiên test có số lượng lớn kết quả, ví dụ G(S,B) đạt cực đại với test mà từng Si chỉ chứa một case đơn. Tiêu chuẩn gain ratio giải quyết được vấn đề này bằng việc đưa vào thông tin tiềm năng (potential information) của bản thân mỗi phân hoạch.
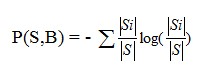
Test B sẽ được chọn nếu có tỉ số giá trị gain ratio ![]() lớn nhất.
lớn nhất.
Trong mô hình phân lớp C4.5, có thể dùng một trong hai loại chỉ số Information Gain hay Gain ratio để xác định thuộc tính tốt nhất. Trong đó Gain ratio là lựa chọn mặc định.
Chuyển đổi sang luật: cắt tỉa cây
- Dạng luật: if A and B and C… then class X. Không thỏa mãn điều kiện chuyển về lớp mặc định.
- Xây dựng luật: 4 bước
- Mỗi đường đi từ gốc đến lá là một luật mẫu. Đơn giản luật mẫu bằng
cách bỏ dần điều kiện mà không ảnh hưởng tới độ chính xác của luật. - Các luật đã cắt tỉa được nhóm lại theo giá trị phân lớp tạo ra các tập
Với mỗi tập con, xem xét để lựa chọn luật để tối ưu hóa độ chính
xác dự đoán của lớp gắn với tập luật đó. - Sắp xếp các tập luật trên theo tần số lỗi. Lớp mặc định được tạo ra
bằng cách xác định các case trong tập S không chứa trong các luật hiện tại và chọn lớp phổ biến nhất trong các case đó làm lớp mặc định. - Ước lượng đánh giá: các luật được ước lượng trên toàn tập S, loại bỏ
luật làm giảm độ chính xác của sự phân lớp.
- Mỗi đường đi từ gốc đến lá là một luật mẫu. Đơn giản luật mẫu bằng
- Hoàn thành: 1 tập các quy tắc đơn giản được lựa chọn cho mỗi lớp


")

")




")
{kind=link}